In some cases the lexer built into xtext (which uses Antlr3) may not be configurable enough to do what we want. It would be very nice if xtext allowed a preprocessor to modify the input to the parser. We could write a lexer completely by hand but usually we want the lexer to be derived from the grammar but in a more customised way than currently allowed by Xtext.
Therefore this page is looking at the possibilities for customising the lexer. Examples or the need for this include:
- When we need a preprocessor.
- When we are adapting an existing grammar to use with xtext (for example in trying to Implement Aldor I need virtual semicolons inserted after some closing braces).
- When we need to implement macroes in out language (example and code here).
- When indents (whitespace) is used to indicate blocks (example and code here).
What I would really like, in order to do these things, is a preprocessor.
I get the impression from other posts that this is very difficult because it needs and additional mapping table between text regions in JFace editor and references to these text regions in XText. This mapping would have to be applied in multiple places deep in the Xtext code and it would be very difficult for an XText user to do this.
I would really like this capability to be built in to Xtext but I get the impression, from your blogs, that you consider XText to be feature complete so I am guessing this is not likely to happen soon?
I have therefore implemented something simpler here.
This is a 'phantom token', that is, a token that is used by the parser but does not appear in the text. (The inverse of a ).
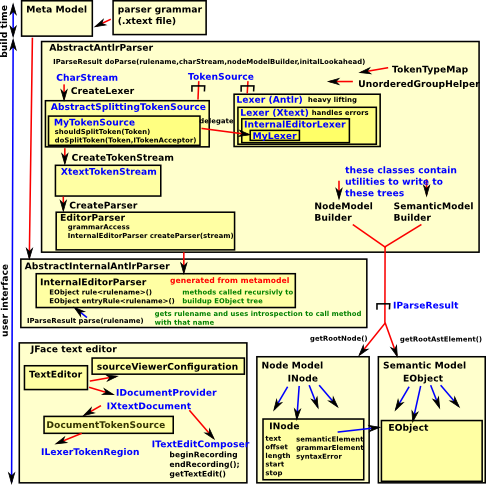
Xtext parser generates two interlinked tree structures:
- EMF model (semantic model) - used for validation and eventually code generation - I think this is the equivalent to the AST.
- Node Model - This is read by the Eclipse JFace text editor component to display and enter the text. Leaves in this tree are tokens which point to a chunk of text stream which must be contiguous and non-overlapping with other tokens.
It is the interlinking between these two tree structures which allows the IDE capabilities.
this customisation is limited and there is a requirement for a 1:1 mapping (many:one mapping not allowed) between these two tree structures. This makes it very hard to support macros as they would require a many:one mapping.
However, as described on this thread, xtext does not have this capability built-in and it would be very hard for DSL designers to implement it. I am therefore investigating the possibility of doing some of these things by customising the lexer.
Token Splitting
Antlr has support for 'splitting token', that is, the ability to replace a single token with multiple tokens and Xtext supports this here: AbstractSplittingTokenSource.
Xtext have some example code for blocks based on indentation on the github site here.
and generated code.
Inserting Tokens
One of the ways I would like to customise the Lexer is to be able to insert extra tokens into the Lexer output. My first application for this is my translation of the Aldor grammar, here I am transferring an existing grammar from YACC into xtext. Apart from this LR(1)->LL(*) translation I want to keep the grammar as similar as possible and Aldor inserts virtual semicolons after some closing braces so it would help if I could do the same in xtext. (If I was defining the grammar from scratch I would not do it this way but in this case I really need to) .
In the future I have applications in mind where blocks are denoted by whitespace and so, this time, I would like to insert '{' when indent increases and '}' when indent decreases.
The easiest way to implement these types of application seems to create a custom lexer which mostly uses the generated lexer but overrides 'nextToken' as I have done here. Most of the time this code works fine but sometimes I get a validation error. This is because the tokens point back to the text in the JFace text editor and it expects this mapping to be disjoint and contiguous which will not be the case for the inserted tokens.
So what want to do is remove these extra nodes from the node model (by modifying NodeModelBuilder) but leaving the semantic model.
There are examples, for instance, Python-like whitespace block delineation and macroes here.
Default Setup
In 'src-gen' we have 'AbstractEditorRuntimeModule.java' which includes:
// contributed by
// org.eclipse.xtext.generator.parser.antlr.XtextAntlrGeneratorFragment
public void configureRuntimeLexer(com.google.inject.Binder binder) {
binder.bind(org.eclipse.xtext.parser.antlr.Lexer.class).annotatedWith
(com.google.inject.name.Names.named
(org.eclipse.xtext.parser.antlr.LexerBindings.RUNTIME))
.to(com.euclideanspace.aldor.parser.antlr.internal.InternalEditorLexer.class);
}
|
Which binds:
public class InternalEditorLexer extends Lexer { |
| The Antlr file: runtime.Lexer is extended in xtext and the nextToken() and mTokens() methods are overridden. | 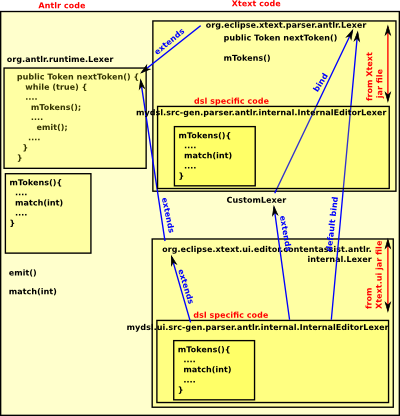 |
Options
In the Antlr code there are two places we could override.
Token nextToken()
Return a token from this source; i.e., match a token on the char * stream.
void mTokens()
This is the lexer entry point that sets instance var 'token'
Customising
In order to do this we have to override this code in xtext.
import org.antlr.runtime.MismatchedTokenException;
import org.antlr.runtime.NoViableAltException;
import org.antlr.runtime.RecognitionException;
import org.antlr.runtime.Token;
import org.eclipse.xtext.parser.antlr.Lexer;
public class MyLexer extends Lexer {
@Override
public void mTokens() {
// implement lexer here
}
}
|
Then bind it in the module:
@Override
public void configureRuntimeLexer(Binder binder) {
binder.bind(Lexer.class)
.annotatedWith(Names.named(LexerBindings.RUNTIME))
.to(MyLexer.class);
}
; |
For an example of this see hastee.
Emitting Multiple Tokens
If we want to generate multiple tokens for a given match (For example to add phantom semicolon after closing brace) then we need to be able to emit multiple tokens like this:
import org.antlr.runtime.CharStream;
import org.antlr.runtime.RecognizerSharedState;
import org.antlr.runtime.Token;
import java.util.Deque;
public abstract class Lexer extends org.antlr.runtime.Lexer {
// Defer to the original constructors
public Lexer() { super(); }
public Lexer(CharStream input) { super(input); }
public Lexer(CharStream input, RecognizerSharedState state) { super(input, state); }
// Multi-emitting, as above
Deque |
For more information about grammar see this page.
