This page follows on from some introductory information that I have put about Xtext here.
The main definition of the language is done by editing the file with the '.xtext' extension. For simple Xtext projects this may be the only file you need to configure. This file defines the following:
- Lexer - This defines how the language is divided up into the components of the language such as keywords, operations, names and so on. I have put more about the lexer on this page.
- Grammar - this defines the actual structure of the language, this is defined as a set of rules, more information below.
- Mapping to Model - it is not enough to be able to recognise a grammar, we also need to map it onto an ecore model, the ecore model can then generate the language editor and so on. More information about the ecore model here and mapping the grammar to it on this page.
Grammar
The body of the Xtext grammar file is a list of rules, in the grammar file (which has an .xtext extension), written by the person implementing the DSL.
There is not space in this page to give a full explanation of the theory of language grammars, if you are not familiar with this theory you will need to learn about the following topics:
Xtext uses Antlr parser which uses LL(*) algorithm . This does not allow left recursive grammars (see this blog post by Sven Efftinge about how to avoid left recursion in expressions). Note XText does not support ANTLR4 which uses a new adaptive parsing strategy, this accepts any grammar and converts it to LL(*), unfortunately in XText we still have to avoid left recursion by hand.
One of the first decisions is to work out the primitives required and which of these are handled by the lexer.
Lexer
Terminal rules, each terminal rule returns an atomic type.
| Syntax Element | Means |
|---|---|
| . | wild card |
| ! 'x' | invert (not x) |
| ('0'..'9') | character range |
More information about the lexer on this page.
Grammar
Removing Left Recursion
Xtext (and antlr3) does not allow left recursion so we need to remove it.
Binary Operation Example
Here we look at removing left recursion in a binary operation rule, in this case '+'.
The following would be an intuitive way to define addition but it is left (and also right) recursive:
Expression: Atomic | left=Expression '+' right=Expression ; |
- where 'Atomic' is a number without '+' in it.
We can remove this left recursion in a right or left associative way as follows:
right associative:
Expression:
left=Atomic ('+' right=Expression)?
; |
- where '?' suffix means one or none instances.
left associative:
Expression:
left=Atomic ('+' right=Atomic)*
; |
- where '*' suffix means any number (zero or more) of instances.
Syntax Elements of Grammar
| Syntax Element | Means |
|---|---|
| default (no operator) | exactly one |
| ? suffix | one or none |
| * suffix | any (zero or more) |
| + suffix | one or more |
| | infix | or |
| & infix | unordered group |
Cross References
Square brackets represent a cross reference, that is a non-containment reference.
| Syntax Element | Means |
|---|---|
| [t|n] | cross reference to an (already existing) object of type' t' via a name that has the syntax of 'n' |
Where:
- t=ReferencedEClass: type of referenced object
(not grammar rule but an EClass ) - n=CrossReferenceTerminal: string returning grammar rule.
Used to cross reference to referenced object.
If the CrossReferenceTerminal is not explicitly included then it will default to ID, that is, [Type] is a shorthand for [Type|ID]
More about cross references on this page.
Syntactic Predicates
=> Means that this option can be parsed it should do so without considering any other alternatives.
example:
The traditional example for syntactic predicates is the dangling else-problem shown by this grammar:
'if' Expression (=> 'else' Expression)?
This tells Xtext that if it can parse an 'else' it should do so without considering any other alternatives.
- I have discussed syntactic predicates further on page here.
- There is also some useful information on this external reference.
Construction of AST
The grammar file not only defines the syntax of a text file, but also how it maps to an ECore model.
There are 4 types of rule.
| Rule type | Returns | identified by | Used by |
|---|---|---|---|
| Parser Rules | EClass | Parser | |
| Enum Rules | EEnum | start with 'enum' | Parser |
| Datatype Rules | EDatatype (EString is implied if none has been explicitly declared) | rules that do not:
|
Parser |
| Terminal Rules | EDatatype | start with 'terminal' | Lex |
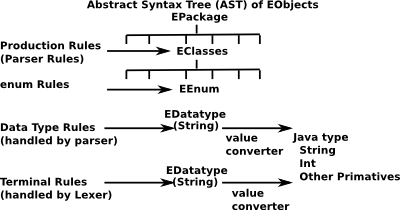
If we want a Syntax element to map to a model element then we should precede it with one of the following forms:
| Syntax Element | Model Element |
|---|---|
| myName = | |
| myName += | returns list |
| myName ?= | returns true/false |
Name Provider
The name provider is responsible for giving a name to an object so that it may be referenced. The following uses naming:
- Cross referencing, such as when using the bracket syntax like: [Type|ID]
- Used as default in label provider (affects outline view, hyperlinks and content proposals,)
The default behavior uses the following conventions:
If an object has a feature with a string-type, whose name is 'name', the default name provider implementation will use the value of that feature for calculating the name of an object.
Magic Names
Generally names can be anything except the following have special meaning:
| Syntax Element | Means |
|---|---|
| name | Supports cross referencing. If an object has a feature with a string-type, whose name is 'name', the default name provider implementation will use the value of that feature for calculating the name of an object. |
| importURI | URI of a model file whose objects should be made visible. Supports URI import of a particular file like this: Where STRING is a rule with string value |
| importedNamespace | A namespace import normally looks as follows:
Import: 'import' importedNamespace=FqnWithWildCard; FqnWithWildCard: Fqn('.*')?; Fqn:ID('.'ID)* |
There is more information about how these are used on this page also on this Itimus blog.
question
Why does this grammar work?
Import returns EuclidImport : 'import' ( importedNamespace=QualifiedName | importedNamespace=QualifiedNameWithWildCard) ';'? ;
But not this?
Import returns EuclidImport :
'import' importedNamespace=QualifiedName ('.' '*')? ';'?
;
Other Naming Conventions
| ID | |
| INT | |
| DOUBLE | |
| STRING | enclosed in single or double quotes |
Actions
Enclosed in braces
Simple Actions
Just a name in braces, this creates a return type.
{BinaryExpression}
Regular Actions
creates a return type and also assigns what has been parsed so far (current) to some variable.
{BinaryExpression.left=current}
Expression: Atom ({BinaryExpression.left=current} op=('+'|'-') right=Atom)*
Debugging
Debugging parser code that has errors can be very difficult to debug.
An error such as:
"Decision can match input such as 'else' using multiple alternatives: 1, 2 As a result, alternative(s) 2 were disabled for that input"
May not be too bad but some errors don't give much information and can be hard to find. Usual program debugging techniques such as breakpoints don't work.
I find it helpful to generate syntax diagrams (railroad diagrams) to be able to see the syntax. but if that does not help then we may need to use ANTLRWorks (use the Ctrl-Shift-R shortcut).
See this blog for more information.
Customising
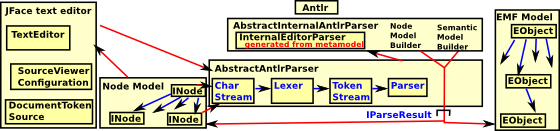
If our DSL cannot easily be parsed using the built-in capability of Xtext then it is possible to customise the lexer or parser.
For instance, Python-like whitespace block delineation and macroes can be difficult in Xtext, I have provided some information here to show how this can be done.
Further Reading
In addition to the xtext documentation, its necessary to get a wider understanding of parsing and how Antlr works.
Parsing expressions is a tricky thing to implement, due to the need to avoid left recursive parser rules, this blog post by Sven Efftinge is very helpful in explaining how to do it.
On the same subject this blog about Pre- and postfix operators in Xtext is also worth reading.
On this site, I have some more pages about specific aspects of parsing grammars:
