This is one of a set of pages about the Axiom CAS and its forks, particularly FriCAS, these pages start here. This particular page specifies an approximate syntax for SPAD.
The FriCAS/Axiom code is written in a language called SPAD, for an overview of this language see this page. SPAD is very powerful and also quite experimental in its structure, it does not easily map onto a syntax that a conventional parser could use (perhaps its not even possible). There are disadvantages to the way that the current parser works, its not easy to specify its operation, its difficult to change, error messages are unhelpful and it does not allow modern IDE tools to be used.
Although it may not be possible/practical to specify the SPAD exactly we can get very close. I have implemented the syntax proposed on this page as a program for editing FriCAS code. This program can fully parse over half of the FriCAS algebra library and the remaining files only have a few remaining errors.
- I have described this program here.
- The full source code is here.
- The file which specifies the syntax is this one.
FriCAS parses SPAD using a type of parser known as a 'Pratt' parser. In this type of parser each operator has different binding powers for its left and right. The SPAD parser also has 'special handlers' for certain operators. In this type of parser there is less distinction made between expressions and statements, effectively everything is treated as an expression so in this context, not only are "+" and "*" operators but also other keywords such as "for" and "return".
This is quite difficult to use with Eclipse/Xtext because program blocks are usually indicated by whitespace (pile mode). In order to allow us to parse SPAD I have written a 'front-end' to the parser which:
- Adds braces when the indentation changes (except in comments/empty lines).
- Substitutes Macros.
- Lines ending in '_' are concatenated.
- Bracketed statements on single line are converted to braces.
However whitespace is still significant, in that statements are not separated by semicolon ';' but require a new line, which makes the parser harder to write than it would otherwise be.
The code to do this runs when these files are read into the SPAD project (usually when the project is created). Therefore the user sees the code with these changes applied. I don't really know a practical way to undo these changes when the editing has been done and the program is saved.
In order to construct this syntax I started with the LED and NUD tables which specify how SPAD is interpeted (and compiled?). These tables give the operator and keyword precedences, from which we can start to buld the syntax. These tables are shown on this page.
Here we are using a LL(*) recursive-descent parser generator and this may not be able to exactly replicate the SPAD parser as described above
I have taken this information from s-parser.boot in src/interp so I suspect that it in valid only for the SPAD interpreter and not the compiler however I am hoping that this will be a close enough approximation for this purpose.
Model
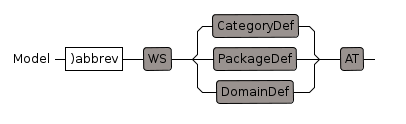
CategoryDef,PackageDef and DomainDef must end with newline to ensure that only an '@' at the start of a line will be taken as the end.
On this line whitespace (WS) is not hidden so is explicitly included.
CategoryDef

The body of the category is defined by the 'WherePart' rule (following the 'where' keyword).
This, in turn, contains rules 'WithPart' and 'AddPart'.
Sometimes, due to a slightly different syntax the add part is outside the 'WherePart'.
Not every category has a 'WithPart' or a 'AddPart'. |
 |
longname and longname2 should both be ID and have the same value as the name of the category. Since the runtime values can't be checked by the parser this must be checked later.
PackageDef

As with category above the body of the package is defined by the 'WherePart' rule (following the 'where' keyword).
Similar comments to those in category apply regarding the 'WithPart' and 'AddPart' rules. |
 |
longname and longname2 should both be ID and have the same value. Since the runtime values can't be checked by the parser this must be checked later.
DomainDef

The syntax of DomainDef is the same as PackageDef except that a domain has a 'Rep' although that is not checked by the parser so, at the parser level, they are the same.
WherePart

Both category and domain can have 'where' part which holds overall information such as category/domain parameter information and general macros. This is followed by export('with') and import ('add') information.
Forms allowed include:
- Exports == PlottablePlaneCurveCategory with {
- Exports ==> PlottablePlaneCurveCategory with {
- Exports ==> with {
WhereAssignments
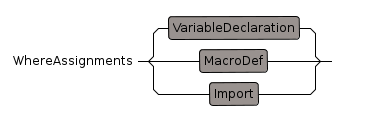
each one must be on a separate line or separated by ';'
need to add name=
WithPart

the 'where' part contains a 'with' part which holds export information such as function signatures (function declarations) but not function definitions.
WithInline

similar to 'WithPart' but no trailing NL
AddPart

the 'where' part contains a 'add' part which holds function and other declarations.
AddStatements
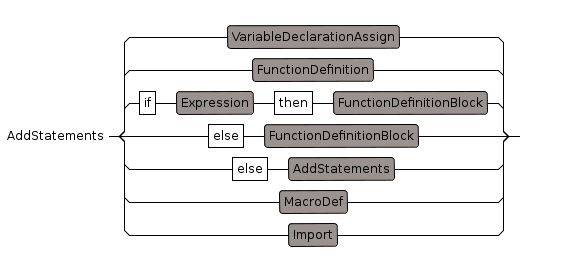
The add section of domain or package may contain multiple lines
Examples:
if (r := recip leadingCoefficient M) case "failed" then {
error "Modulus cannot be made monic"
}FunctionDefinition
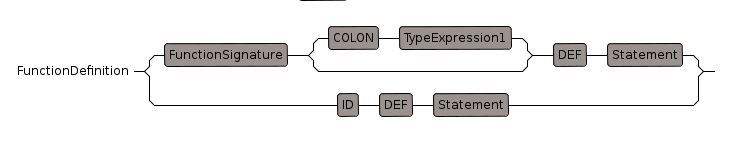
Function definition in add part (called by AddStatements).
* has a form like:
name(params) == statement
or, option for single parameter without brackets:
name param == statement
or, option for zero parameters without brackets:
This does not always work at the moment, for instance, this does not work:
size == size$R ^ d
but this does
size() == size$R ^ d
or, for infix operators,
a = b == statement
or, for multiple statements,
name(params) == {
statement
statement
}
some function definitions may be conditional like this:
if % has finiteAggregate then {
* ... }FunctionDefinitionBlock
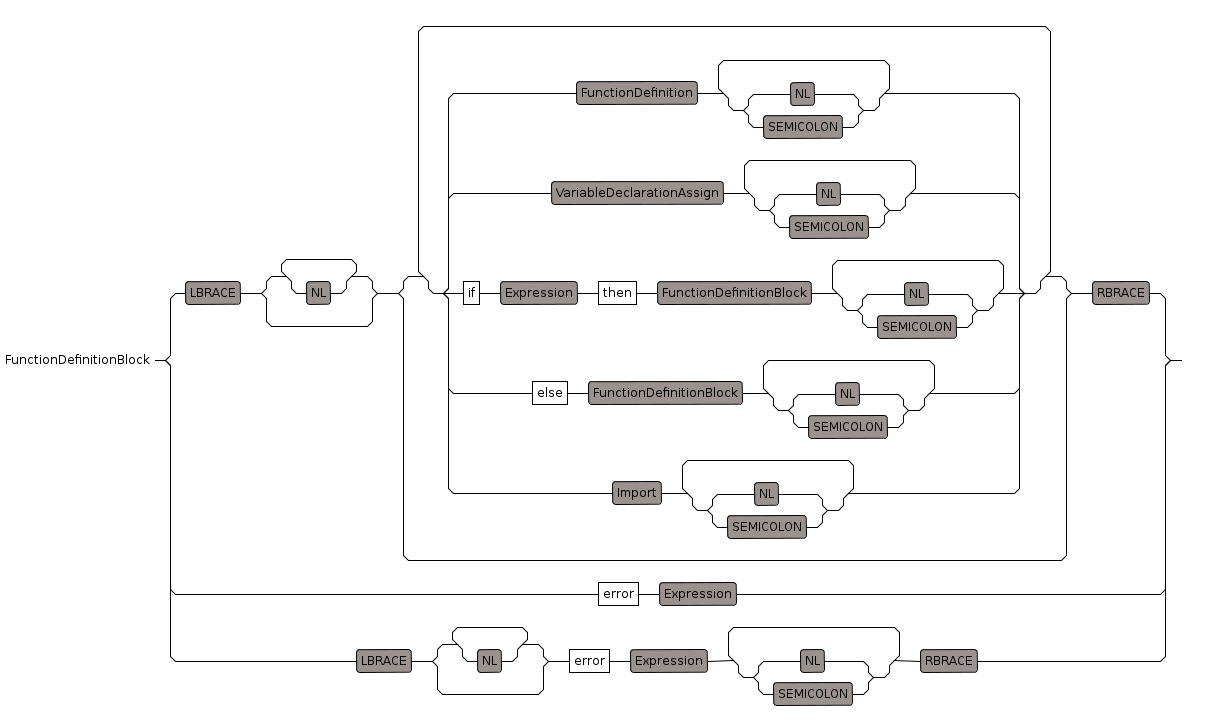
Called by 'AddStatements' rule.
Allows more add statements inside:
if a has y then 'more add statements'
FunctionSignature
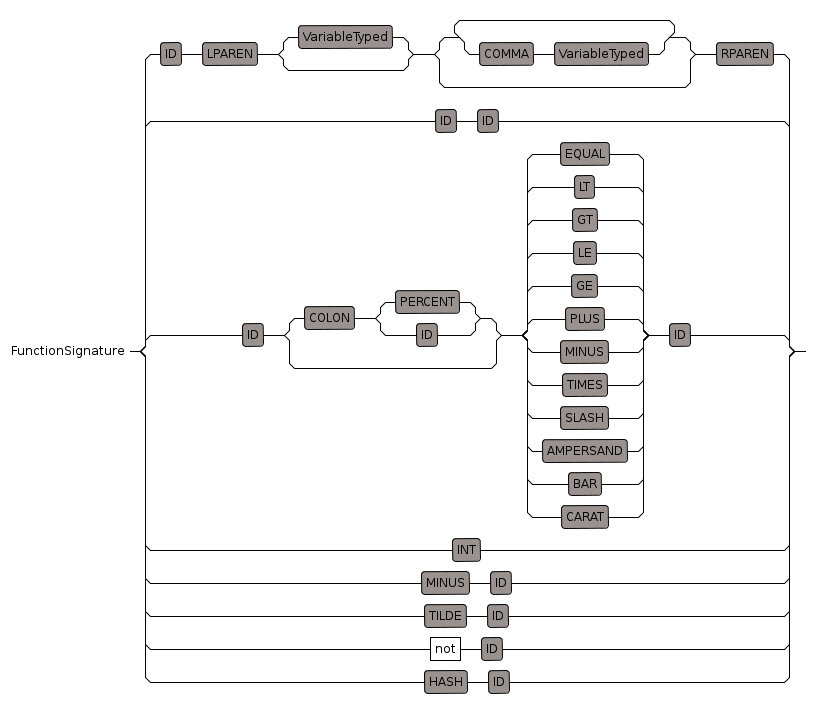
This is the first part of the function definition without the return type or the function implementation.
| Usually the function signature has a form like: |
name(params) |
| We allow a single parameter to be given without brackets: |
name param |
| We also allow some alternative forms to represent infix operators like: |
a = b to represent _=(a,b) |
| or the following (this works but only for % we need it to work for every type) |
s:% = t:%
or
a > b to represent _>(a,b) |
| can be used as a function signature as a short form of _0() or _1() |
0
or
1 |
MacroDef
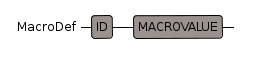
macros provide a general textual substitution. There are two forms:
- name ==> body
- name macro == body
Import

import domain
VariableDeclarationBlock

Variable declaration in where and with sections:
| A 'variable' can be simple like: |
x:Float |
| or something more complicated like: |
x:Record(newPt: Pt,type: String) |
| or it can be a function like: |
x:(Float,Integer) -> Float |
| or it can be conditional like: |
if S has SetCategory then x:S |
| |
|
VariableDeclaration

This rule declares a variable/function. It is not yet defined or used but just declared.
This is used in 'where' and 'with' parts.
Variable declaration in 'where' and 'with' sections. This is often a function declaration but we can also declare an ordinary variable.
| A 'variable' can be simple like: |
x:Float |
| or something more complicated like: |
x:Record(newPt: Pt,type: String) |
| or it can be a function like: |
x:(Float,Integer) -> Float |
| or it can be conditional like: |
if S has SetCategory then x:S |
| |
|
TypeWithName

This rule is used where a type is expected like:
but it may also have an optional name like:
VariableTyped

Variable name with optional type. This is used in function signature and also by VariableDeclaration:
| A 'variable' can be simple like: |
x:Float |
| or something more complicated like: |
x:Record(newPt: Pt,type: String) |
| or it can be a function like: |
x:(Float,Integer) -> Float |
| we can define multiple variables together: |
i,j : Integer |
| |
|
VariableDeclarationAssign

in add part we can declare and assign in same part such as:
- a := 3
- a:Integer := 3
- a := sin(x)
There are two forms of multiple assignment:
- a,b,c := 0@Integer
- a := b := c := 0@Integer
Variable
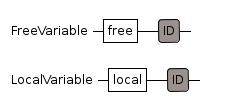
free variable allows us to declare a variable that is global
allows us to declare a variable that is not global
TypeExpression (and TypeExpression1,TypeExpression2)
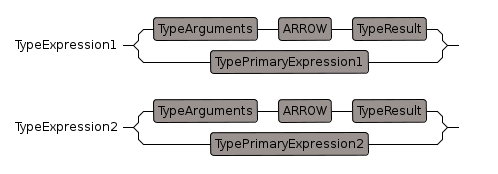
This is similar to Expression but known to be of type. (Expression can also be of type) but if we know that this is a type we can exclude some possibilities.
Ideally, at the syntax level, I think there should be no distinction between 'expressions' and 'type expressions', just 'expressions' which could be either type. However I have not managed to achieve this yet. I have discussed this issue further on this page.
A 'typeExpression' can be simple like:
or something more complicated like:
- Record(newPt: Pt,type: String)
or it can be a function like:
first we check for a function like: Integer -> Integer
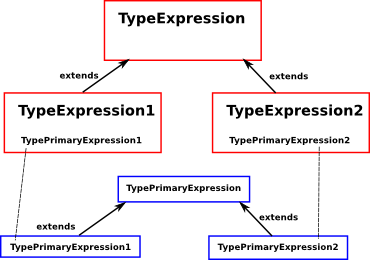
TypeExpression2
This is the same as TypeExpression except it does not allow the type to be extended by using a 'with' keyword. It is used in the 'where' rule because the 'with' in that case has a slightly different syntax.
TypeParameterList
We use a type parameter list for parameters of category, package or domains
Parameter list may be empty '()'.
in this case parameters may be just ID or they may be nameID:typeID
examples are:
- ()
- (String)
- (s:String)
- (String,Integer)
- (s:String,i:Integer)
TypedArguments
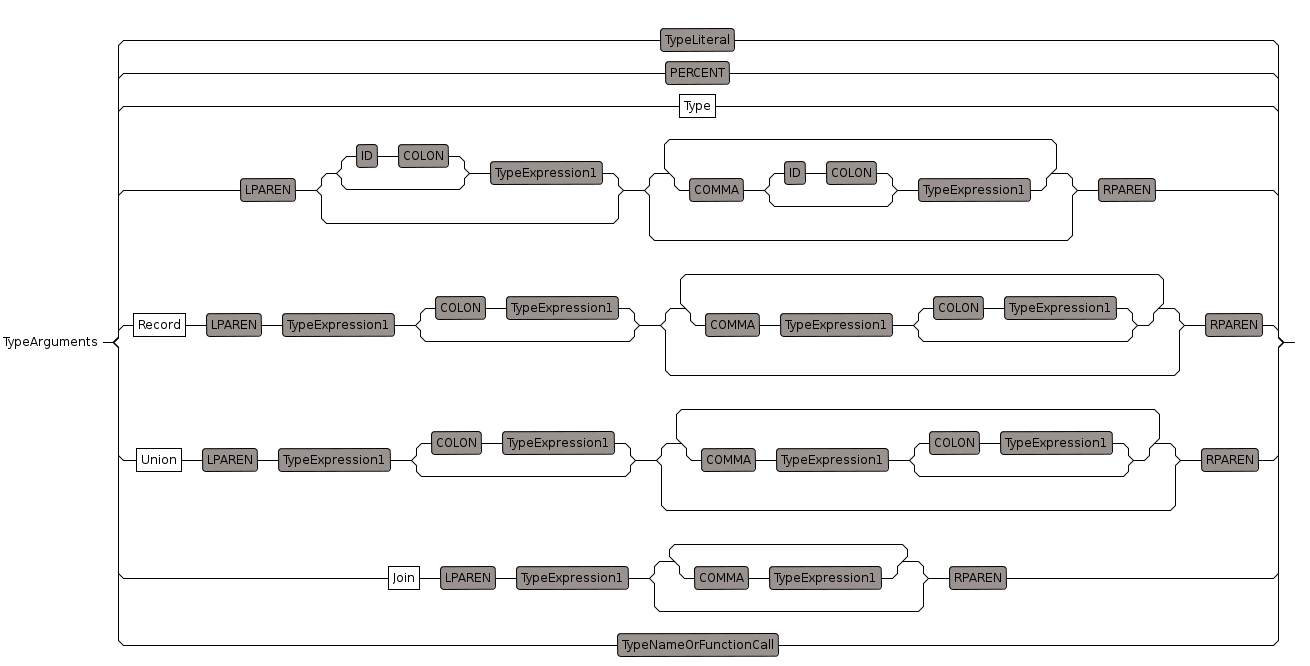
we use type arguments for first part of function type, that is
x in x-> y
usually this is enclosed in parenthesis
(x) in (x)-> y
but if x is a single argument (Including Record, Union, etc.) then it does not need to be in parenthesis.
TypeResult
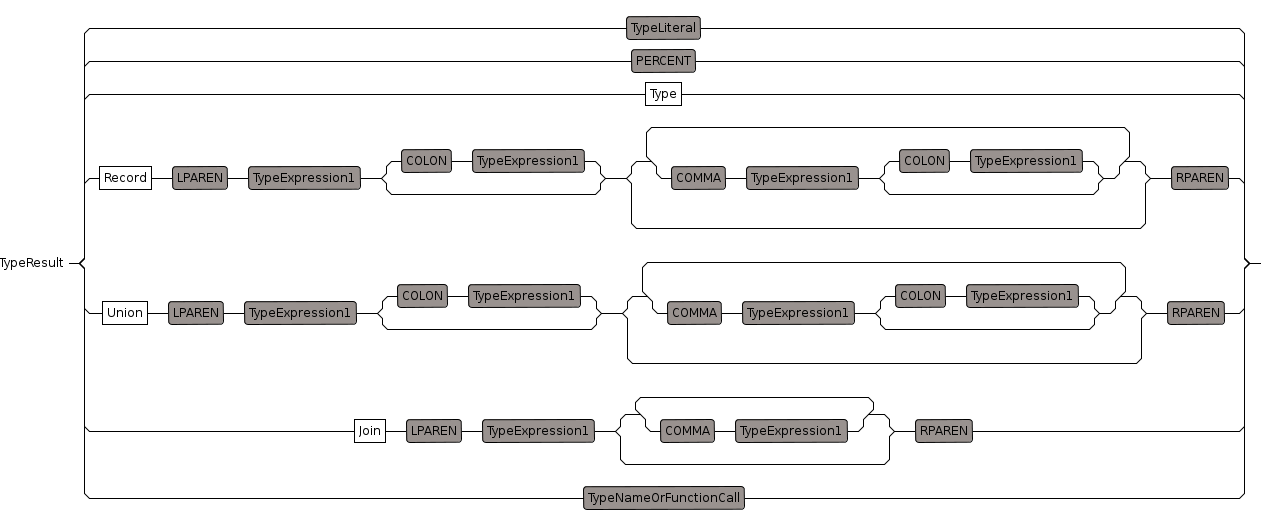
we use type arguments for final part of function type, that is
y in x-> y
TypePrimaryExpression (and TypePrimaryExpression1,TypePrimaryExpression2)
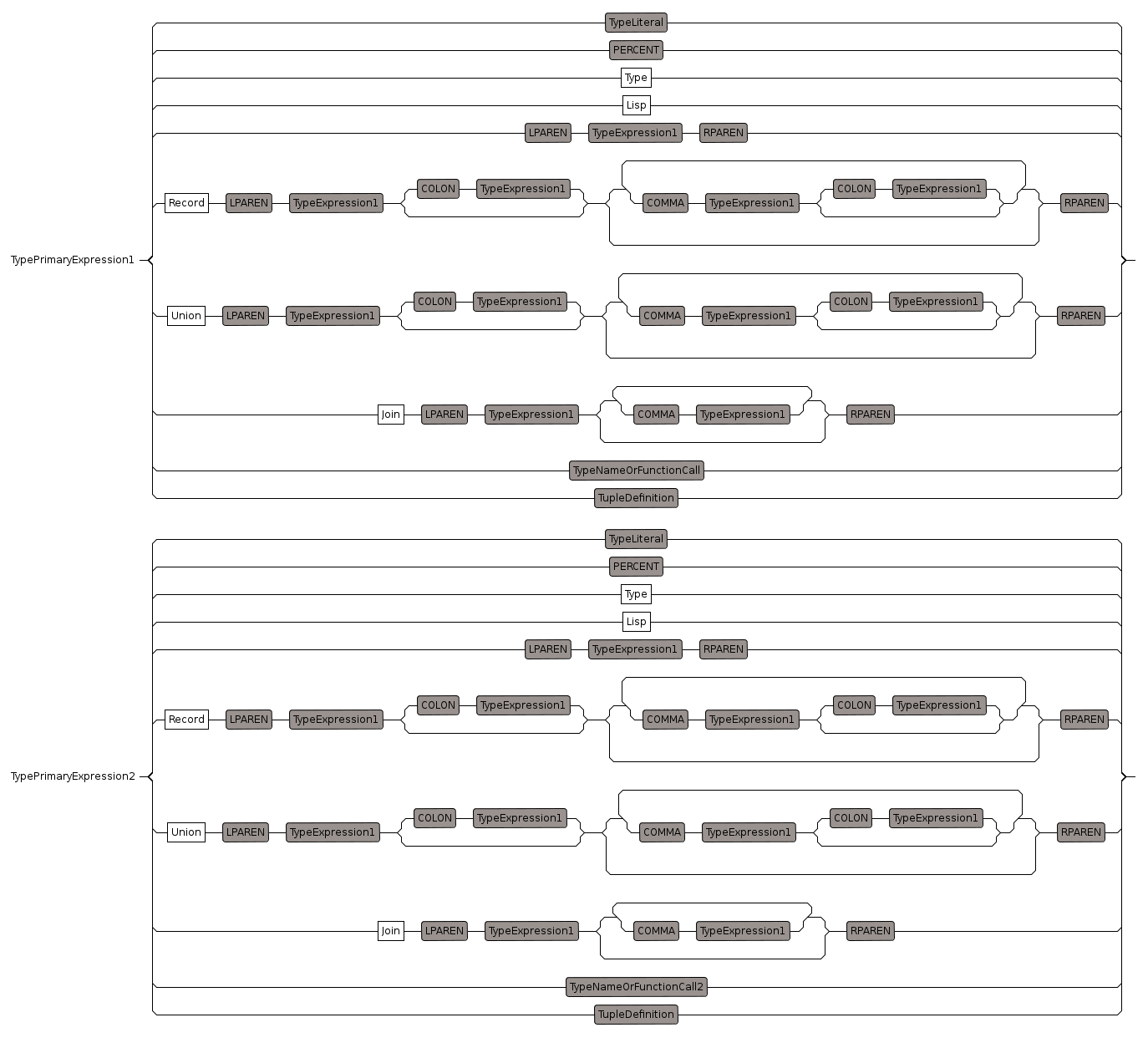
this matches various specific types
TypePrimaryExpression2
This is the same as TypePrimaryExpression except it does not allow the type to be extended by using a 'with' keyword. It is used in the 'where' rule because the 'with' in that case has a slightly different syntax.
TypeNameOrFunctionCall
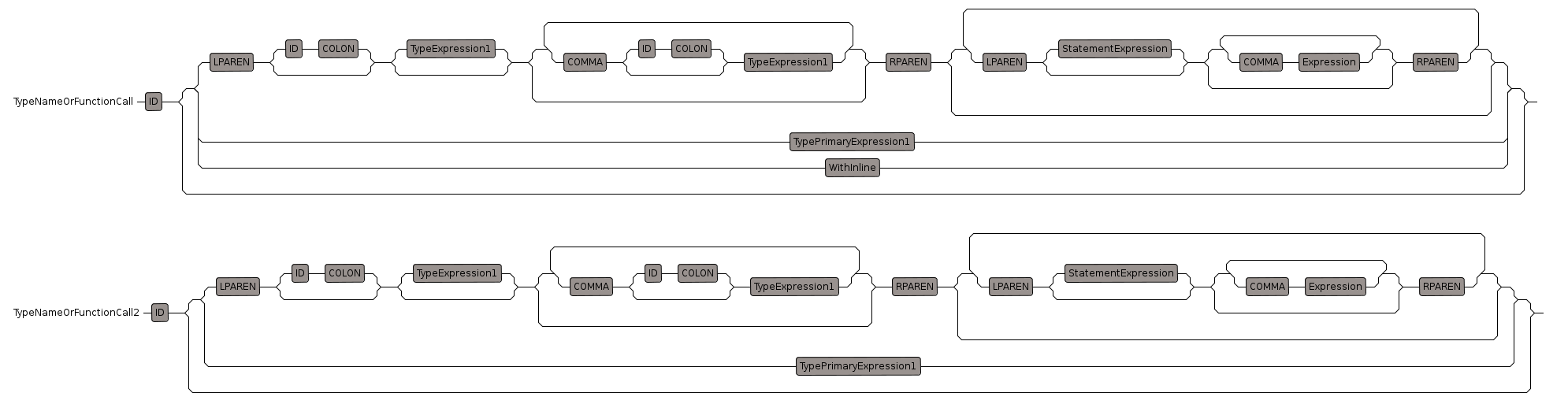
This rule will match:
- Float - an ID representation of a type
- List(Float) - a type function call
- List Float - a non-parenthesis form if only one parameter
A type function is also known as a parameterised type or functor (not necessarily a true functor since it may not obey the axioms of a functor).
If there is only one parameter then the parenthesis are optional
TupleDefinition

This has a form like: (Integer,Float,String)
like an array where each entry can be of a different type
TypeLiteral
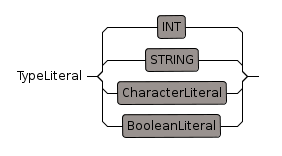
Since SPAD supports dependent types then numbers and strings can occur here.
Outstanding issues:
- Float literals are parsed as elt(Int,Int) so we need to recognise this and convert to float literal
- We need to be able to recognise exponent notation for floats
- Integers without '-' prefix can be converted to PI or NNI
- need to add hex or octal notation for integers (0xhhhh)
- String and Character literals need to have backslash "\" doubled to "\\" otherwise xtext will interpret backslash as an escape character.
- values following immediately after string literal such as "abc"d should represent an implied concat: concat("abc",d)
Statement
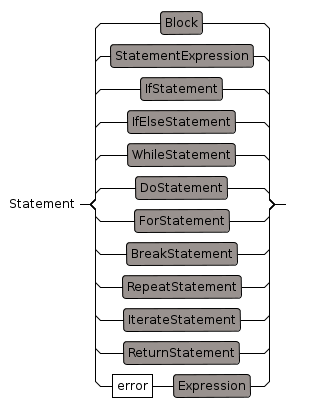
In FunctionDefinition the algorithm is defined by a sequence of the following statements:
Block
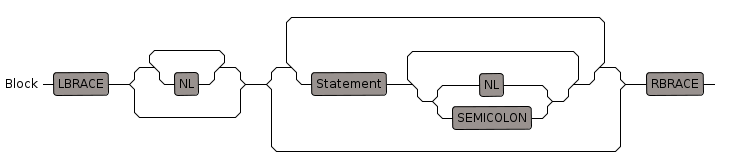
Allows multiple statements which are grouped by wrapping in braces (curly brackets).
StatementExpression

Gives a value or assigns a value to a variable or does conditional exit
examples:
- x
- x:Int
- x,y:INT -- multiple assignment
- x:Int := 3
- x=y => 3
ForStatement

- for i in n..m repeat ... is 1
- for i in n..m by s repeat ...
- for i in list repeat ...
- for i in list for i in 1..length() repeat ...
- for i in list for i in 1.. repeat ...
- for j in n..m repeat loopBody
- for j in n..m | odd? j repeat
To Do
As a temporary measure we check for '..' as a suffix operator here, but we should really put this into expression?
We need to allow conditions using BAR '|'
WhileStatement
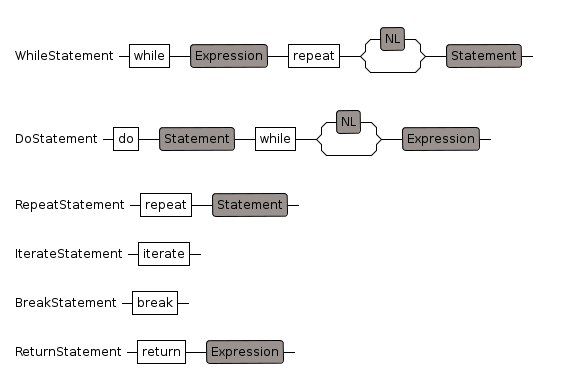
while BoolExpr repeat loopBody
Do
do loopBody while BoolExpr
RepeatStatement
will repeat until we jump out. For instance by calling return.
IterateStatement
iterate ...
skips over the remainder of a loop
BreakStatement
break leave current loop
ReturnStatement
return leave current function
ImportStatement
import - use 'Import' instead
If Statement
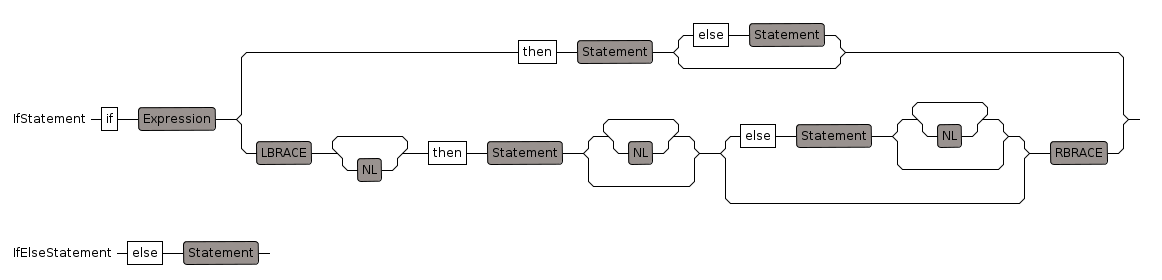
'if' statement allows program flow to be switched
forms:
- if boolean then
- if equation then
- if ... not ... and ...or ... then
- if ... then ... else ...
note1:
if ... then ... else ... always returns a value so we can use this on the right hand side of an assignment
note2:
since there is an explicit 'then' keyword there is no need to put the condition in brackets
examples:
a:= if x >0 then x else -x
if R has Field then ...
if myUnion case mtType then ...
we also need to allow a form like this:
if x >0 {
then x
else -x
}
also this form (this requires IfElseStatement rule):
if x >0 then {
x
}
else {
-x
}Expression

This is the top level for expressions
This level handles special cases such as:
if x then y else z
(x,y) +-> z
We can consider expressions as elements of statements
Expressions contain no newlines unless preceded by underscore (which is handled by WS)
Exit Expression

condition '=>' expr1 ';' expr2
Condition Expression

- BAR "|" precedence: 108, 111
Or Expression
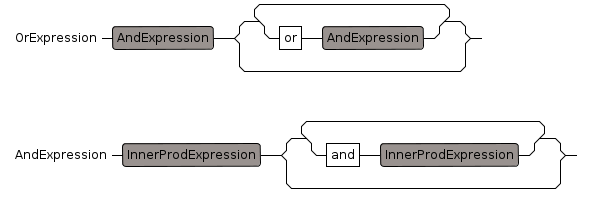
There is also another rule that looks for 'or' which is PredicateOr, this version is used in a general expression and the other version is used when we know we have a predicate.
- "or", precedence: 200, 201
And Expression
There is also another rule that looks for 'and' which is PredicateAnd, this version is used in a general expression and the other version is used when we know we have a predicate.
- "and", precedence: 250, 251
InnerProduct Expression
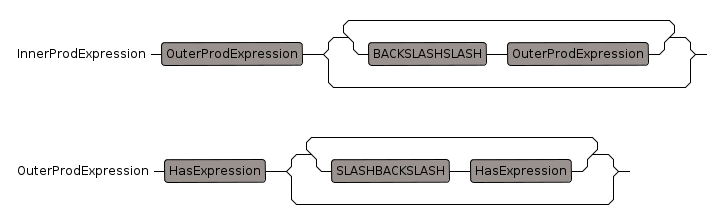
This has multiple uses such as inner product and logical or.
- "\/", BACKSLASHSLASH precedence: 200, 201
The backslash is duplicated here because it is the escape character for strings, it will not be duplicated when used.
OuterProdExpression
This has multiple uses such as outer product and logical and.
- "/\", SLASHBACKSLASH precedence: 250, 251
The backslash is duplicated here because it is the escape character for strings, it will not be duplicated when used.
Has Expression
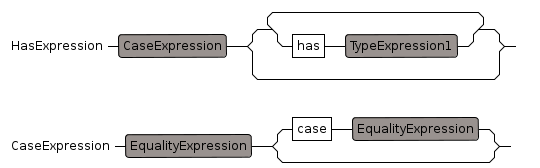
Predicate which returns true if preceding value is of a given type or inherits from the type. Test is done at compile time so it does not test runtime values.
example:
if R has Field then ..
- "has", precedence: 400, 400
Case Expression
Select from Union values, example:
if myUnion case mtType then ...
- "case", precedence: 400, 400
In Expression
used in list comprehension
- "in", precedence: 400, 400
Equality Expression
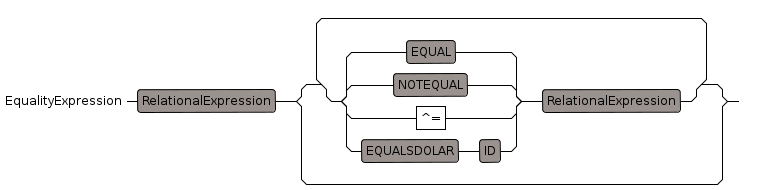
- "~=", precedence: 400, 400
- "^=", precedence: 400, 400
- "=", precedence: 400, 400
Relational Expression
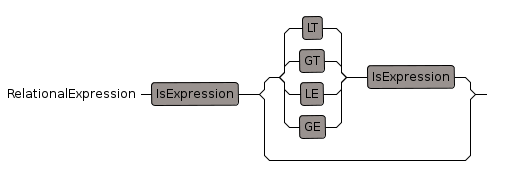
- ">=", precedence: 400, 400
- "<=", precedence: 400, 400
- ">>", precedence: 400, 400
- "<<", precedence: 400, 400
- ">", precedence: 400, 400
- "<", precedence: 400, 400
Is Expression
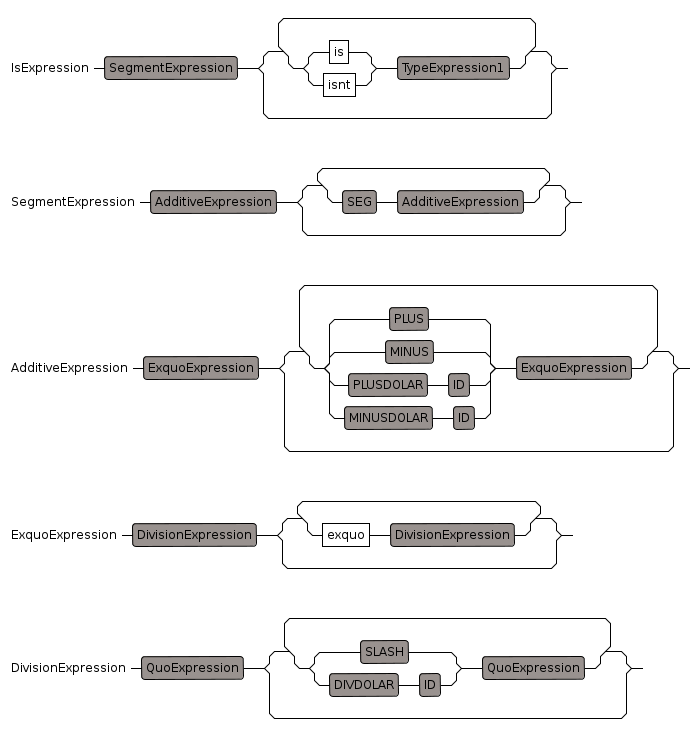
IsExpression
Predicate which returns true if preceding value is of a given type. Test is done at compile time so it does not test runtime values.
- "isnt", precedence: 400, 400
- "is", precedence: 400, 400
Segment Expression
this is used to indicate a range:
- 1..4 means the range from 1 to 4
- 1.. means the range from 1 to infinity. This is used in cases where no top bounds is necessary, when the end point is determined by other means.
"..", "SEGMENT", precedence: 401, 699, ["parse_Seg"]
Additive Expression
We include both '+' and '-' in the same case as this allows a multiple sequence like:
a + b + c - d + e -f
- "-", precedence: 700, 701
- "+", precedence: 700, 701
Exquo Expression
"exquo", precedence: 800, 801
Division Expression
division expression
"/", precedence: 800, 801
Quo Expression
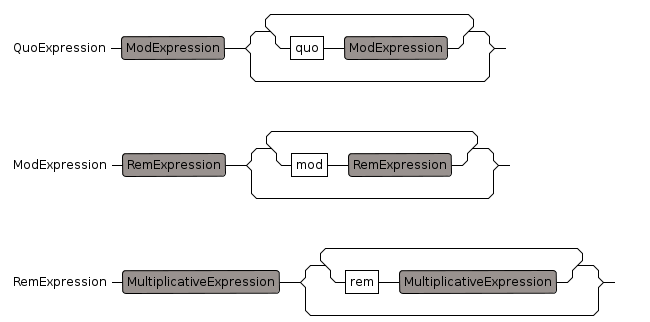
quo", precedence: 800, 801
Mod Expression
"mod", precedence: 800, 801
Rem Expression
"rem", precedence: 800, 801
Multiplicative Expression
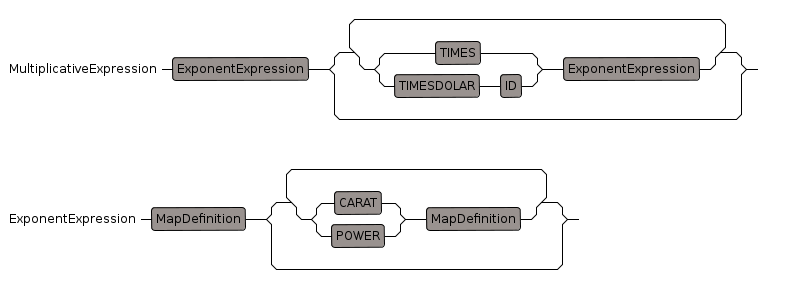
multiplication expression
a * b * c
"*", precedence: 800, 801
Exponent Expression
* "^", precedence: 901, 900
* "**", precedence: 901, 900
Map Expression
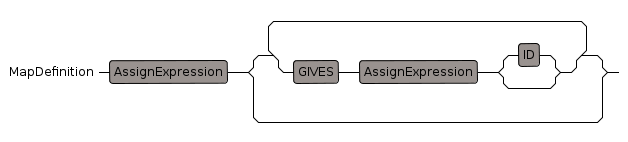
Map or Lambda expression
var +-> function
+-> is an infix operator meaning 'maps-to'
It can be used to create a function literal (an anonymous function), so instead of:
myFunct(x:Type):Type == if x >0 then x else -x
we can have forms such as:
x +-> if x >0 then x else -x
or:
(x,y) +-> if x >0 then y else -x
fricas compatibility: "+->", precedence: 995, 112
Assign Expression

An assign expression like this:
x := y
Can also be an inner assign like this:
x := (y := z)
or just:
x := y := z
right is expression to allow forms like
x := if y<0 then -y else y
Pretend Expression
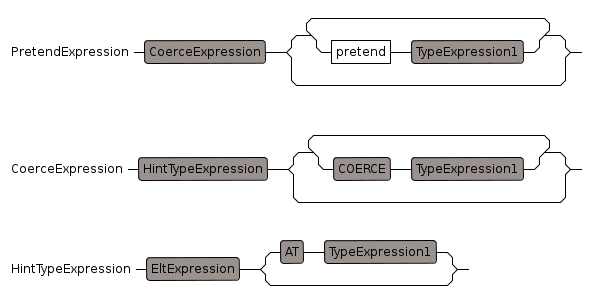
Pretend Type: treat one type as another, only works if they have the same internal structure.
Not very safe and should be avoided, if possible, unfortunately its not always possible to avoid.
"pretend", precedence: 995, 996
Coerce Expression
"::", precedence: 996, 997
although '::' and '@' apparently have the same precidence we want '@' to bind more tightly than '::'. As we can see in the following example:
"dictionary"@String :: OutputForm.
HintType Expression
"@", precedence: 996, 997
Bang Expression
We treat these as part of the language
- : indicates type
- ! is part of name to indicate mutable
- ":", precedence: 996, 997
- "!", precedence: 1002, 1001
With Expression
"with", precedence: 2000, 400, ["parse_InfixWith"]
Elt Expression
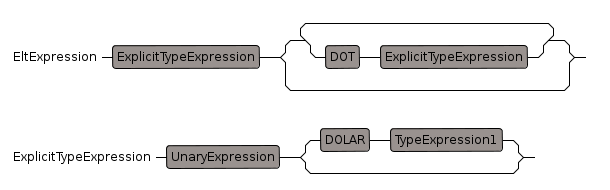
Elt is Lisp terminology for the use of '.' to select parameters
The left expression is something that has selectable elements such as a list, array, string, Record or union, the right element should be a non-negative integer.
ExplicitType Expression
Unary Expression
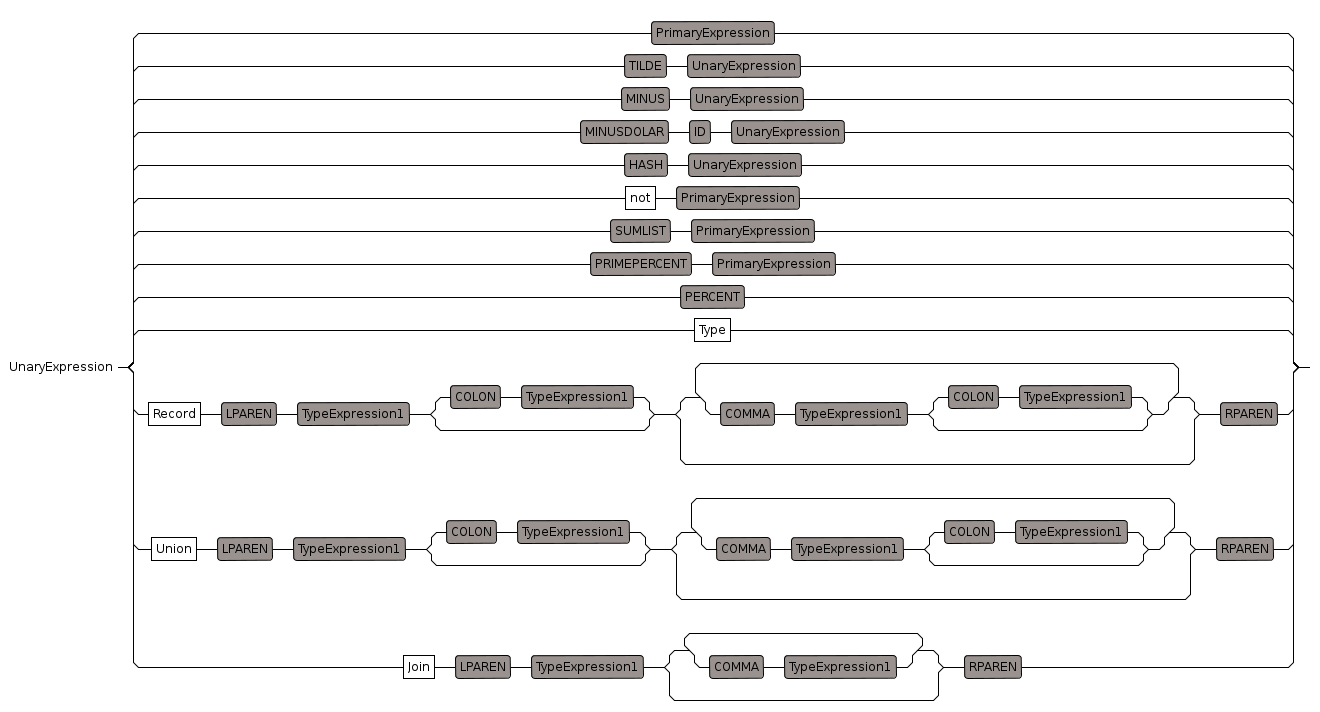
unary prefixes:
- "~" TILDE : precedence 260, 259, nil
- ":" COLON : precedence 194, 195
- "-" MINUS : precedence 701, 700
- "#" HASH : precedence 999, 998
- "'" : precedence 999, 999, ["parse_Data"]
unary suffixes
- ".." : range can be unary suffix
Unary ExpressionHash
Primary Expression
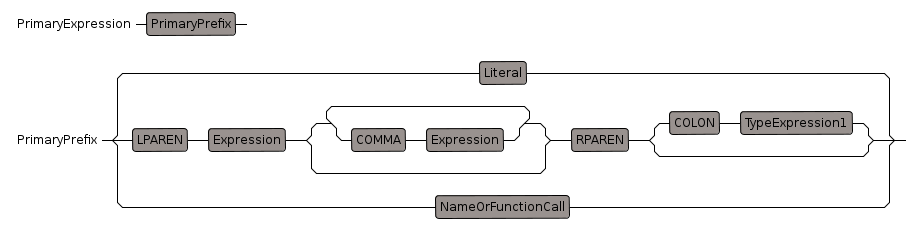
Can contain an expression in parenthesis, this expression is 'StatementExpression' which means that it can contain an inner assignment.
The comma option allows us to define a tuple
NameOrFunctionCall

function call such as List(Integer) known as a parameterised type or functor (not necessarily a true functor since
it may not obey the axioms of a functor)
if there is only one parameter then the parenthesis are optional
function binds most tightly
Literal
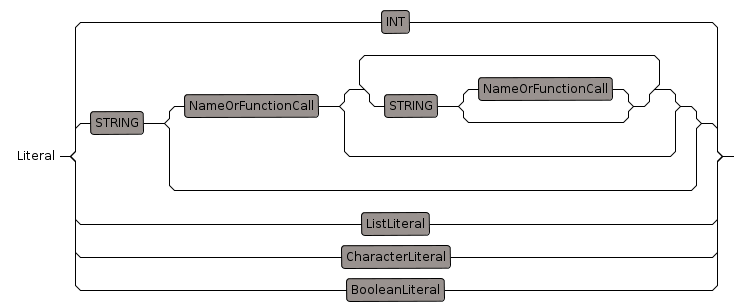
Literals are actual values of a given type
Outstanding issues:
- Float literals are parsed as elt(Int,Int) so we need to recognise this and convert to float literal
- We need to be able to recognise exponent notation for floats
- Integers without '-' prefix can be converted to PI or NNI
- need to add hex or octal notation for integers (0xhhhh)
- String and Character literals need to have backslash "\" doubled to "\\" otherwise xtext will interpret backslash as an escape character.
- values following immediately after string literal such as "abc"d should represent an implied concat: concat("abc",d)
CharacterLiteral
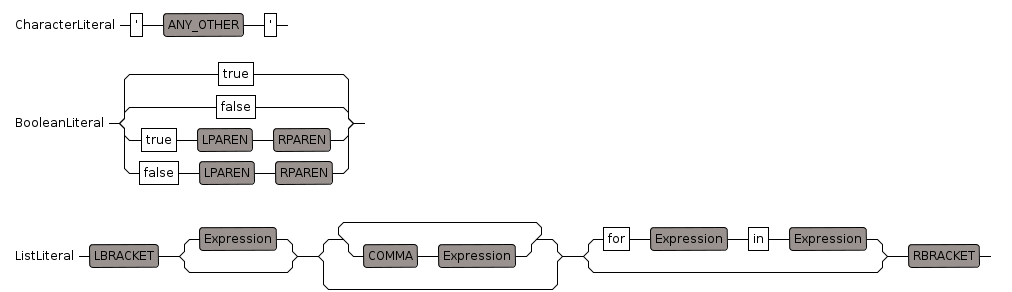
Contains a single character whereas a string contains multiple characters.
BooleanLiteral
This may not need to be specified here at the syntax level. Perhaps we should treat boolean as any other library defined type.
ListLiteral
A list literal may consist of:
- [] an empty list
- [a] a single element
- [a,b] multiple elements
- [a for b in c] a list comprehension
In order to analyse SPAD code we need to:
- Break into blocks using pile or curly brackets.
- Apply macroes
- Parse
This site may have errors. Don't use for critical systems.